DRAFT
This is as an update to an earlier post1, in which the goal is to increase the size of a golden dataset in order to help compare the query performance between two embedding models, all-MiniLM-L12-v2 and all-mpnet-base-v2 and the comparison is important because they are 384 and 768 dimensions respectively, meaning that the second one has twice the storage costs as the other and live postgresql storage is expensive not just for its storage but also for the storage of the hnsw indexes involved 😅.
TLDR, with additional data and additional metrics, the objective evidence continues to support that the lower dimension model is actually better and so the justification exists not to spend the extra money. And this is also interesting empirical evidence that a larger model means it will be better for your specific use case.
Summary
For the two models, and the three metrics we have,
┌───────────────────┬────────────┬──────────┬──────────┬────────┐
│ model_name ┆ dimensions ┆ map ┆ mrr ┆ p@k=10 │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ f64 ┆ f64 ┆ f64 │
╞═══════════════════╪════════════╪══════════╪══════════╪════════╡
│ all-MiniLM-L12-v2 ┆ 384 ┆ 0.715203 ┆ 0.925 ┆ 0.65 │
│ all-mpnet-base-v2 ┆ 768 ┆ 0.664065 ┆ 0.920833 ┆ 0.5875 │
└───────────────────┴────────────┴──────────┴──────────┴────────┘
More about the MAP, MRR and Precision@K=10
I describe MAP and MRR in the last post1. And Precision@K=10 is to say, that if the first 10 search results are probably going to be first ones someone looks at and likely the only ones someone looks at, then why not create a metric that judges only on the proportion of hits out of 10, ignoring all the later results 11, 12 and so on?
Details about the golden dataset
Here, I went from 21 queries to 24 queries and also increased the number of documents in the corpus. In particular, now, the corpus had at least 10 relevant documents per query as opposed to prior with only sometimes 5.
The document count was increased to 10 actually specifically inspired by a desire to compare the embedding models using Precision@K=10. 😀.
This is also important since fractions with small denominators skew the average worse. (100 would be better than 10 of course but one step at a time haha.)
And I also added a new metric, Precision@K=10, that is the proportion of the first K=10 search results that is relevant, averaging across all queries, alongside the earlier two metrics. The other two metrics were, MAP Mean Average Precision and MRR Mean Reciprocal Rank .
I also looked at a hit/miss bitmap to get a visual sense too
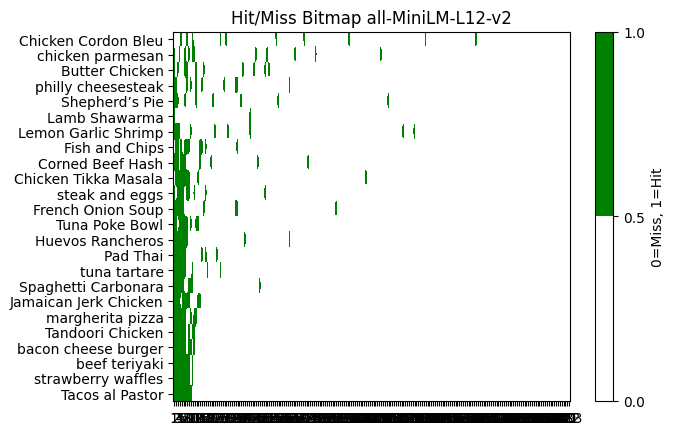
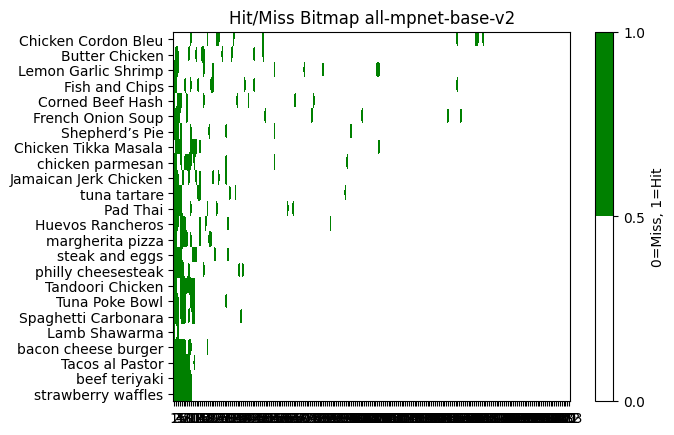
TODO notes
I should also discuss the use of onnx to reproduce the all-MiniLM-L12-v2 model locally, in order to make the analysis even possible. This was pretty cool.