Recently, I had been interested in locally reproducing the typesense huggingface models on my laptop. I want to experiment with the https://typesense.org nodes, but I also want to be able to use the same embedding models on my laptop for local development.
I noticed that the models in the typesense section of hugging face are in the model.onnx format which I had not encountered before. I learned how to get them running locally and I was able to compare that the vectors on a typesense cluster I was running matched vectors I generated locally.
However, I was extending the model from single query embedding to batch embedding yesterday and I stumbled upon the weirdness bug of one query being embedded differently depending on whether I embedded it alone versus in a batch. Eventually I understood what my bug was and after facepalming, wrote up and tested a fix!
Setting up the onnx model locally
So I learned that the typical huggingface python library was not sufficient here.
install a new library
cd ~/.python_venvs
uv venv --python 3.11 dish
source dish/bin/activate
which python # /Users/michal/.python_venvs/dish/bin/python
python --version # Python 3.11.7
uv pip install ipython
uv pip install optimum[onnxruntime]
And I downloaded the config.json model.onnx vocab.txt three files to a new folder, onnx_models/all-MiniLM-L12-v2.
actually it took a few attempts to load the model
Initially I was getting a numpy v1 vs v2 error,
from optimum.onnxruntime import ORTModelForSequenceClassification
from transformers import AutoTokenizer
# Load the model
model = ORTModelForSequenceClassification.from_pretrained("all-MiniLM-L12-v2")
# Load tokenizer if available
tokenizer = AutoTokenizer.from_pretrained("all-MiniLM-L12-v2")
# Prepare input
inputs = tokenizer("Hello world!", return_tensors="pt")
# Perform inference
outputs = model(**inputs)
print(outputs.logits)
A module that was compiled using NumPy 1.x cannot be run in
NumPy 2.2.0 as it may crash. To support both 1.x and 2.x
versions of NumPy, modules must be compiled with NumPy 2.0.
Some module may need to rebuild instead e.g. with 'pybind11>=2.12'.
If you are a user of the module, the easiest solution will be to
downgrade to 'numpy<2' or try to upgrade the affected module.
We expect that some modules will need time to support NumPy 2.
Retrying with python 3.9 and numpy 1.x
uv venv --python 3.9 dish # Using CPython 3.9.18 interpreter at: /usr/local/opt/python@3.9/bin/python3.9
source dish/bin/activate
uv pip install ipython optimum[onnxruntime] "numpy<2"
# I saw numpy==1.26.4 , nice!
and now loading was fine,
from pathlib import Path
from optimum.onnxruntime import ORTModelForFeatureExtraction
from transformers import AutoTokenizer
model_name = "all-MiniLM-L12-v2"
local_models = "local_models"
path_to_local_all_minilm_l12_v2 = (Path.home() / local_models / model_name).as_posix()
# Load the model
model = ORTModelForFeatureExtraction.from_pretrained(path_to_local_all_minilm_l12_v2)
tokenizer = AutoTokenizer.from_pretrained(path_to_local_all_minilm_l12_v2)
# Prepare input
inputs = tokenizer("Hello world!", return_tensors="pt")
# Perform inference
outputs = model(**inputs)
# Retrieve embeddings from last_hidden_state (for example)
embeddings = outputs.last_hidden_state
print(inputs)
print(embeddings.shape) # e.g., [batch_size, seq_length, hidden_dim]
print(embeddings)
{'input_ids': tensor([[ 101, 7592, 2088, 999, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1]])}
torch.Size([1, 5, 384])
tensor([[[-0.1849, -0.0977, -0.0351, -0.2134, ..., -0.0405, -0.2599, 0.1040, 0.1008],
[-0.8934, -0.0513, 0.4190, -0.3306, ..., -0.0511, 0.1419, 0.0011, 0.5171],
[-0.0798, 0.1150, -0.2807, -0.4178, ..., -0.5528, -0.4580, -0.5165, -0.0583],
[-0.3010, 0.9995, -0.0930, -0.1598, ..., 0.0433, -0.3697, 0.5390, 0.1855],
[-0.1849, -0.0977, -0.0351, -0.2134, ..., -0.0405, -0.2599, 0.1040, 0.1008]]])
only thing left to do here is to use mean pooling to get one embedding from the 5 token embeddings,
emb = torch.mean(embeddings[0, :, :], 0)
print(emb.shape)
print(emb)
torch.Size([384])
tensor([-0.3288, 0.1736, -0.0050, -0.2670, ..., -0.1283, -0.2411, 0.0463, 0.1692])
reproduce local embedding model matches what is used on typesense cluster
So I had loaded some food related data on my typesense cluster, ran a simple query to pull a few documents and then re-embedded them locally to check the vectors.
First query my cluster
import torch
from pprint import pprint
torch.set_printoptions(threshold=12, edgeitems=4, linewidth=90)
client = make_client(timeout=600)
location = random_us_coords()
results = query_raw(location, "buffalo wings", 100)
df = df_from_results(results)
df[:5]
pprint([[row["concat"][:37], torch.tensor(row["embedding"]), round(row["vector_distance"], 3)] for row in df[:5].to_dicts()])
[[' fried chicken wings ',
tensor([ 0.0037, 0.0396, -0.9224, 0.1760, ..., -0.0739, 0.3501, -0.3490, -0.1918]),
0.395],
['c bourbon chicken ',
tensor([-0.1860, -0.1894, -0.3629, -0.0392, ..., -0.0728, 0.0968, 0.3149, -0.1836]),
0.478],
['thai crispy wings large chicken wings',
tensor([-0.1742, 0.0064, -0.2367, 0.0564, ..., -0.0186, 0.3364, -0.2523, -0.2709]),
0.541],
['bourbon honey bourbons ',
tensor([-0.5718, -0.0672, -0.0274, -0.0360, ..., 0.3141, 0.1054, 0.4766, -0.3480]),
0.542],
['boar s head buffalo style chicken ',
tensor([-0.0436, -0.0633, -0.3899, 0.0730, ..., -0.2415, 0.0070, 0.1767, -0.0291]),
0.549]]
and compare with local,
for row in df[:5].to_dicts():
text = row["concat"]
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
embeddings_vec = outputs.last_hidden_state
emb = torch.mean(embeddings_vec[0, :, :], 0)
print(text[:37])
print("typesense embedding", torch.tensor(row["embedding"]))
print("local embedding", emb, "\n")
fried chicken wings
typesense embedding tensor([ 0.0037, 0.0396, -0.9224, 0.1760, ..., -0.0739, 0.3501, -0.3490, -0.1918])
local embedding tensor([ 0.0037, 0.0396, -0.9224, 0.1760, ..., -0.0739, 0.3501, -0.3490, -0.1918])
c bourbon chicken
typesense embedding tensor([-0.1860, -0.1894, -0.3629, -0.0392, ..., -0.0728, 0.0968, 0.3149, -0.1836])
local embedding tensor([-0.1860, -0.1894, -0.3629, -0.0392, ..., -0.0728, 0.0968, 0.3149, -0.1836])
thai crispy wings large chicken wings
typesense embedding tensor([-0.1742, 0.0064, -0.2367, 0.0564, ..., -0.0186, 0.3364, -0.2523, -0.2709])
local embedding tensor([-0.1742, 0.0064, -0.2367, 0.0564, ..., -0.0186, 0.3364, -0.2523, -0.2709])
bourbon honey bourbons
typesense embedding tensor([-0.5718, -0.0672, -0.0274, -0.0360, ..., 0.3141, 0.1054, 0.4766, -0.3480])
local embedding tensor([-0.5718, -0.0672, -0.0274, -0.0360, ..., 0.3141, 0.1054, 0.4766, -0.3480])
boar s head buffalo style chicken
typesense embedding tensor([-0.0436, -0.0633, -0.3899, 0.0730, ..., -0.2415, 0.0070, 0.1767, -0.0291])
local embedding tensor([-0.0436, -0.0633, -0.3899, 0.0730, ..., -0.2415, 0.0070, 0.1767, -0.0291])
The bug
So I wanted yesterday, to extend a single text embedding to be batched, to vectorize it in other words. But when I did this, my first iteration of the code had a really weird bug. As I was testing it here is what I noticed, below.
At this point I have a minimal convenience class to wrap the retrieval too
import torch
torch.set_printoptions(threshold=10, edgeitems=2, linewidth=80)
from pathlib import Path
import embedder.onnx_utils as eou
model = eou.LocalOnnx(path_to_local_all_minilm_l12_v2)
queries = ["chicken wings", "chicken parmesan"]
embeddings_separate = torch.stack([model.embed_query(x) for x in queries])
embeddings_batch = model.embed_documents(queries)
print(embeddings_separate.shape, embeddings_batch.shape)
print( embeddings_separate)
print( embeddings_batch)
torch.Size([2, 384]) torch.Size([2, 384])
tensor([[-0.1094, 0.0502, ..., -0.3084, -0.2158],
[-0.1148, -0.0603, ..., 0.1199, 0.0667]])
tensor([[-0.0658, 0.0258, ..., -0.2852, -0.0799],
[-0.1148, -0.0603, ..., 0.1199, 0.0667]])
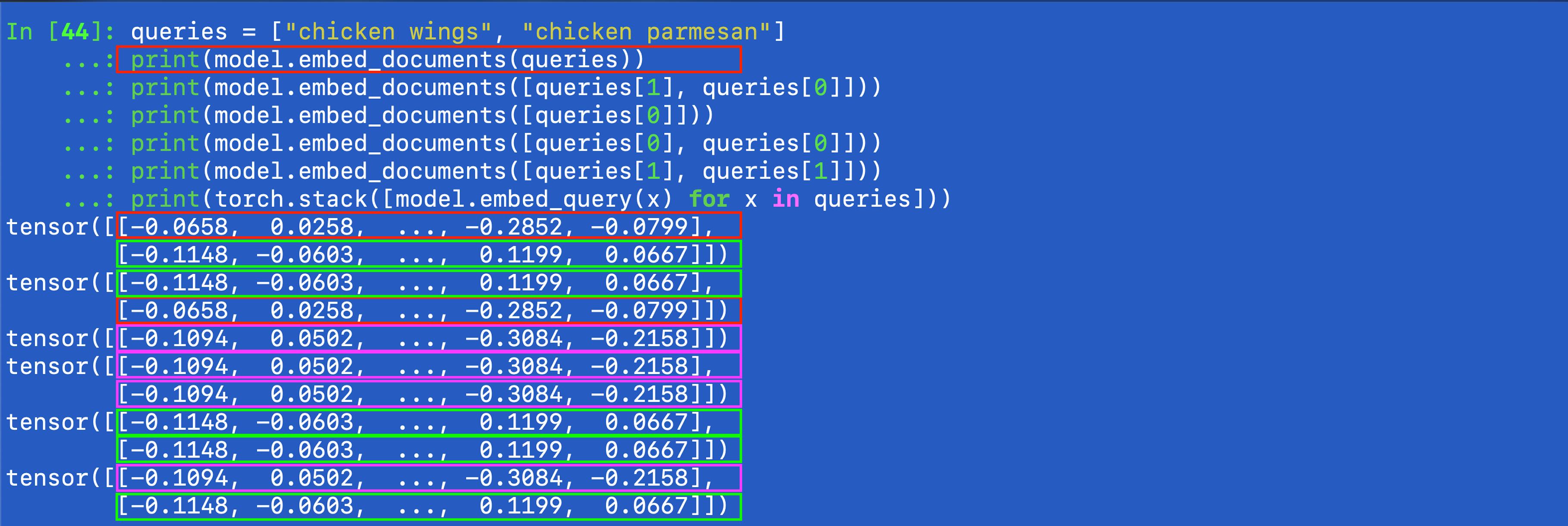
so, clearly one of the vectors was the same batched but not the other.
Looking at it another way I saw this,
So the embeddings from the new model.embed_documents func was different than when running the single model.embed_query, but only for one query. Weird, and flipping the order did not isolate the bug.
queries = ["chicken wings", "chicken parmesan"]
print(model.embed_documents(queries))
print(model.embed_documents([queries[1], queries[0]]))
print(model.embed_documents([queries[0]]))
print(model.embed_documents([queries[0], queries[0]]))
print(model.embed_documents([queries[1], queries[1]]))
print(torch.stack([model.embed_query(x) for x in queries]))
So I also printed the tokens and then I found the smoking gun. (Idea to also look at the intermediate token ideas came from describing my problem to chatgpt!)
queries = ["moroccan peppermint chile", "saudi falafel with mint"]
print(model.embed_documents(queries, print_tokens=True))
print("...\n")
print(model.embed_documents([queries[1], queries[0]], print_tokens=True))
print("...\n")
print(torch.stack([model.embed_query(x, print_tokens=True) for x in queries]))
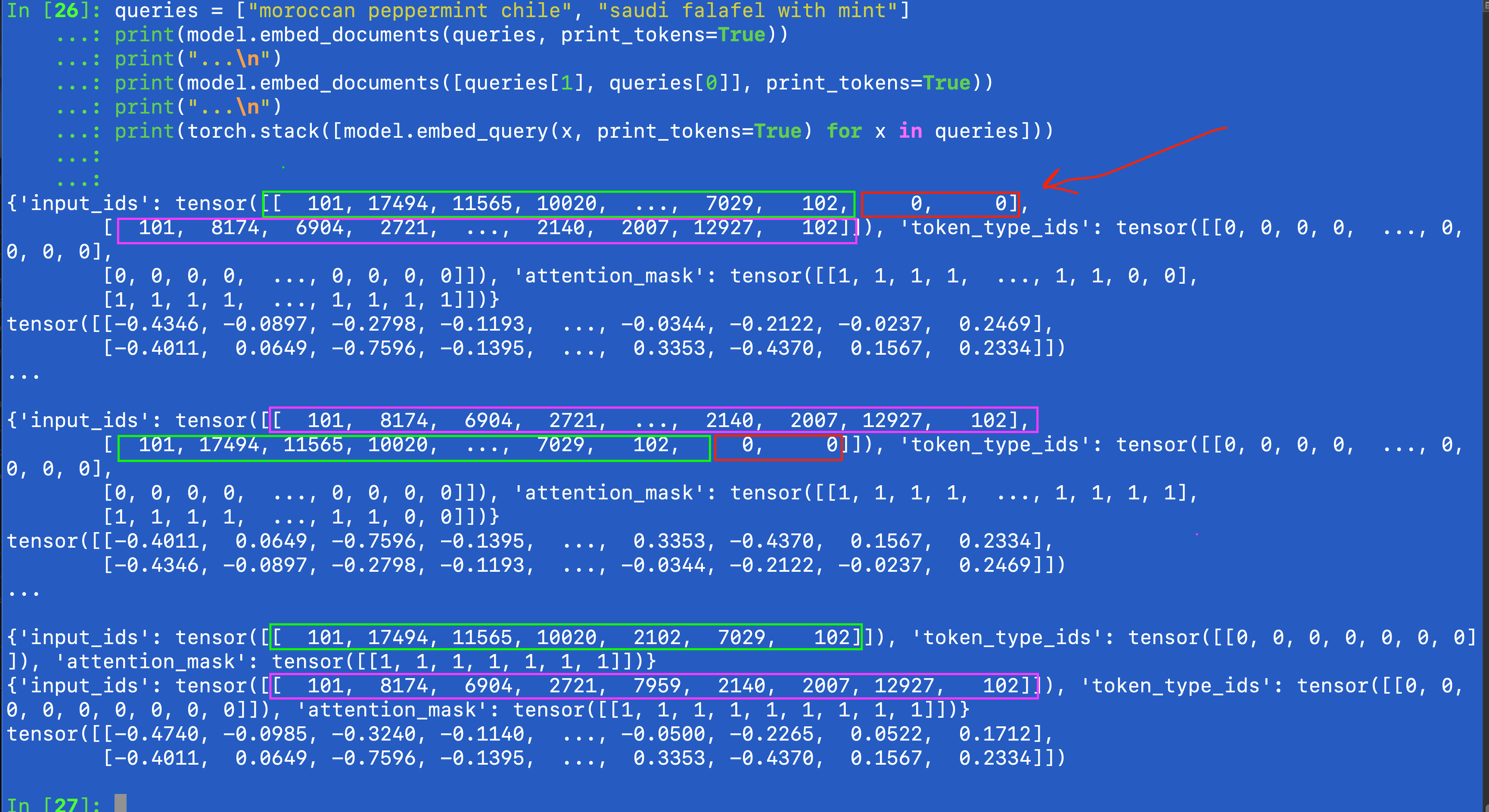
so I realized, looking at the above that ok duhh, the padding is the issue. So looking at the pre-pooling it is more clear even,
The padding
The issue, per the above, was that the query that was being messed up, was the one requiring fewer tokens, and so got padded with two additional 0s . And so when applying the mean pooling, the 0s got averaged in, therefore messing with the final vector.
Also, the whole reason for the padding is, when embedding tokens, in batch, padding must be used because all the transformations work on matrix operations. And without matrices, we get the below error.
from pathlib import Path
from transformers import AutoTokenizer
from optimum.onnxruntime import ORTModelForFeatureExtraction
model_name = "all-MiniLM-L12-v2"
local_models = "local_models"
path_to_local_all_minilm_l12_v2 = (Path.home() / local_models / model_name).as_posix()
tokenizer = AutoTokenizer.from_pretrained(path_to_local_all_minilm_l12_v2)
queries = ["moroccan peppermint chile", "saudi falafel with mint"]
inputs = tokenizer.batch_encode_plus(queries, return_tensors="pt", padding=False)
model = ORTModelForFeatureExtraction.from_pretrained(path_to_local_all_minilm_l12_v2)
outputs = model(
**inputs
)
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length. Perhaps your features (`input_ids` in this case) have excessive nesting (inputs type `list` where type `int` is expected).
the bug
But when padding, the bug was that then after embedding the individual tokens, the code applied [ mean pooling ] (https://sbert.net/docs/sentence_transformer/usage/custom_models.html), naively ignoring the 0 token values,
def embed_documents(self, queries: List[str], print_tokens=False):
inputs = self.tokenizer.batch_encode_plus(
queries, return_tensors="pt", padding=True)
outputs = self.model(
**inputs
)
embedding_vec = outputs.last_hidden_state
embedding = torch.mean(embedding_vec, 1)
print(embedding_vec.shape, embedding.shape)
# torch.Size([2, 9, 384]) torch.Size([2, 384])
and messing with the final embedding.
The resolution
As a new approach, the attention mask that is provided during the encoding is used to remove the pad vectors before taking the mean.
In [13]: inputs
Out[13]:
{'input_ids': tensor([[ 101, 17494, 11565, 10020, ..., 7029, 102, 0, 0],
[ 101, 8174, 6904, 2721, ..., 2140, 2007, 12927, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, ..., 0, 0, 0, 0],
[0, 0, 0, 0, ..., 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, ..., 1, 1, 0, 0],
[1, 1, 1, 1, ..., 1, 1, 1, 1]])}
actually, this is only the first stab and this code can be way cleaner of course, but this solves the problem for now.
def embed_documents(self, queries: List[str], print_tokens=False):
inputs = self.tokenizer.batch_encode_plus(
queries, return_tensors="pt", padding=True)
if print_tokens:
print(inputs)
outputs = self.model(
**inputs
)
embedding_vec = outputs.last_hidden_state
foo_vec = []
# use the mask, after padding, to remove the pad rows.
mask_size = inputs["attention_mask"][1].shape[0]
vector_length = embedding_vec.shape[2]
for i, _ in enumerate(queries):
mask = inputs["attention_mask"][i].bool().view(mask_size, 1).repeat(1, vector_length)
mask_sum = inputs["attention_mask"][i].sum()
emb = embedding_vec[i]
foo_vec.append(
torch.mean(
torch.masked_select(emb, mask).view(mask_sum, vector_length), 0
)
)
return torch.stack(foo_vec)
new run with fix
In [58]: queries = ["moroccan peppermint chile", "saudi falafel with mint"]
...: print(model.embed_documents(queries, ))
...: print("...\n")
...: print(model.embed_documents([queries[1], queries[0]]))
...: print("...\n")
...: print(torch.stack([model.embed_query(x) for x in queries]))
tensor([[-0.4740, -0.0985, -0.3240, -0.1140, ..., -0.0500, -0.2265, 0.0522, 0.1712],
[-0.4011, 0.0649, -0.7596, -0.1395, ..., 0.3353, -0.4370, 0.1567, 0.2334]])
...
tensor([[-0.4011, 0.0649, -0.7596, -0.1395, ..., 0.3353, -0.4370, 0.1567, 0.2334],
[-0.4740, -0.0985, -0.3240, -0.1140, ..., -0.0500, -0.2265, 0.0522, 0.1712]])
...
tensor([[-0.4740, -0.0985, -0.3240, -0.1140, ..., -0.0500, -0.2265, 0.0522, 0.1712],
[-0.4011, 0.0649, -0.7596, -0.1395, ..., 0.3353, -0.4370, 0.1567, 0.2334]])
Appendix
some helper functions
import os
import polars as pl
import typesense
import random
from glom import glom
def make_client(timeout=60):
api_key = os.getenv("TYPESENSE_API_KEY")
cluster_host = os.getenv("TYPESENSE_CLUSTER") # https://cloud.typesense.org/clusters/xxxx
client = typesense.Client({
"nodes": [{
"host": cluster_host,
"port": "443",
"protocol": "https"
}],
"api_key": api_key,
"connection_timeout_seconds": timeout
})
return client
def random_us_coords():
# Continental US approximate bounds:
# Latitude: 24.5°N to 49.5°N
# Longitude: -124.77°W to -66.95°W
lat = random.uniform(24.5, 49.5)
lng = random.uniform(-124.77, -66.95)
return lat, lng
def query_raw(location, query, radius_km):
client = make_client(timeout=600)
lat, lng = location
search_results = client.collections['items'].documents.search({
"q": query,
"query_by": "concat_embedding",
"filter_by":
f"location:({lat}, {lng}, {radius_km} km)",
"sort_by": "_vector_distance:asc",
# "exclude_fields": "concat_embedding",
'page': 1,
'per_page': 100
}
)
return search_results
def df_from_results(results):
spec = [
{
"published_name": "document.published_name",
"concat": "document.concat",
"embedding": "document.concat_embedding",
"vector_distance": "vector_distance",
"location": "document.location",
}
]
df = pl.from_dicts(glom(results["hits"], spec))
return df