motivation
I know more about Databricks for distributed computing. But there is also the Kubernetes world. Let’s read some more on that.
Was wondering hmm, I have used Tensorflow, pytorch on standalone VMs in the past and I know that Spark has its own distributed libraries, so do Tensorflow, pytorch natively support spark, hmm?
lingering questions
- (1) What are the dominant technologies for distributed computing? (spark, and containerization by K8S)
- (2) specifically GPU vs cluster based, are these alternatives?
- (3) Are the typical deep learning options (Tensorflow, pytorch) abstracted by Horovod/ TFJobs or did Tensorflow , pytorch need to be modified to suport multiple clusters ? Wondering about the level of abtraction basically.
- (4) Back prop has some parallelization opportunities , but there are lot of dependencies too. wondering, hmm, what are some parallelization methods w.r.t. what is available?
- (5) are Horovod (and TFJobs) only really for deep learning or how about xgboost?
the dominant architectures/frameworks?
Somehow I got the impression that, since whenever I opened up a google colab notebook in the past and saw GPU set up for tensorflow or pytorch, and then later when I started working with Databricks, I got the impression that GPU and clusters were an either or thing.
I learned
- Not just GPU distributted vs cluster distributed, but also hybrid of these.
- oh and both Databricks and Kubernetes can be used for hybrid.
- But interestingly Databricks / spark, stepped away from distributed. Originally had Spark Deep Learning Libraries, but today, only Horovod and TFJobs .
- Shifted focus, perhaps because lots already options, market saturated .
- Also there are a few others, less widely used, Spark on Ray, and BigDL,
- And Dask, though not particularly for deep learning. (but dask can extend scikit-learn )
- Deep Speed, from Microsoft, but hmm not well known I think.
- Few years ago Google introduced JAX (jax ) as a competitor since pytorch ( facebook ) , grew more popular.
(theory) But that single big vm multiple GPU approach,
I think it is possibly a google colab bias because of convenience? (TODO look more into it.)
But how can you scale back prop?
You might train a small neural net with plain Gradient Descent with back propagation, over a few epochs.
It would fit in memory.
Find the average error for all examples in your dataset,
error = sum squared (target - output)
and then calculate the gradient of the total error w.r.t. each weight in the network, working backwards from the final set of weights, through the hidden layers, to the first layer.
And we apply these as one-time updates to the weights of the network.
what if the dataset doesn’t fit into memory?
The error is additive, so error of the whole dataset, is sum of predictive error, of each row of your dataset.
Consider then mini batches. Randomly split your training set into several smaller sets, find the gradient with respect to all the weights, using the sum squared error of each,
and add the quantities to the weights, for each mini batch.
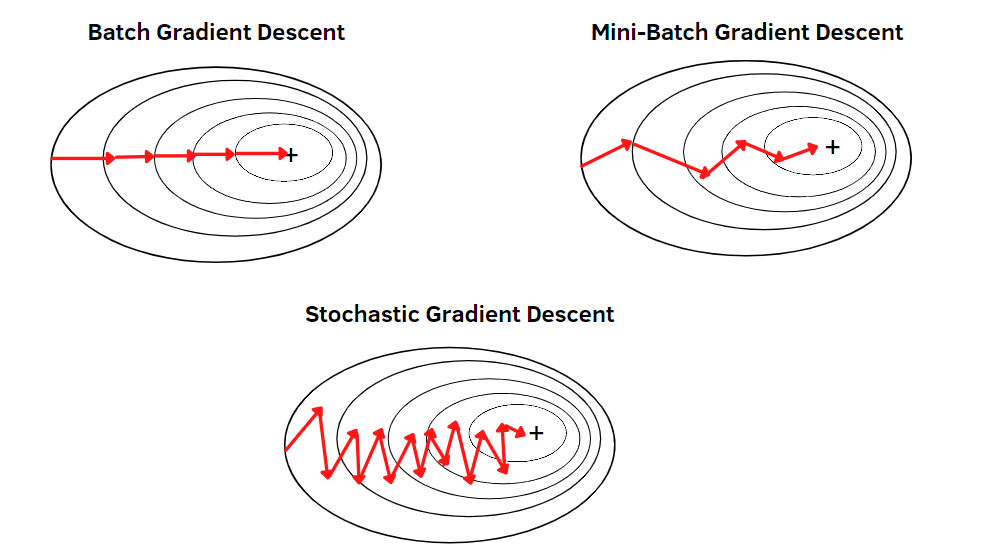
furthermore what if all the weights themselves do not fit into memory of a single GPU ?
This is more complicated.
Now, since back prop is a one layer at a time update, you would need some very tight communication between your nodes (or pods) and here, parallelization, is not for speed but simply out of necessity.
(learned there are some frameworks where there is a parameter server even although a bottle neck !; I think TF has a special worker called a “chief” that helps here, to coordinate the work, including weight initialization, saving checkpoints, logging progress, and helping with failure recovery,)
checkpointing
mainly for recovery from failure, so you can continue from where left off.
asynchronous vs synchronous parameter updates
unclear why this matters (TODO)
tensorflow overtaken by pytorch ?!?
2023 Article , crediting pytorch’s clearer python style. Also siloed vs wide-integrated pytorch ecosystem.
minimal tensorflow
import tensorflow as tf
# Define the model
inp = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
out = tf.nn.softmax(tf.matmul(x, W) + b)
# Initialize the variables and create a session
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# Invoke the model
test_input = None
out_res = sess.run(out, feed_dict={inp: test_inp})
vs
minimal pytorch
import torch
import torch.nn as nn
import torch.nn.functional as F
# Define and Initialize the model
class ExampleNetwork(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 10)
def forward(self, x):
return F.softmax(self.fc1(x), dim=1)
model = Net()
# Run an inference
test_input = None
out = ExampleNetwork(test_inp)
Tensorflow 2
Yes ther was the TF2 rewrite , but looks like Google ’s current answer is JAX.
references
- in 2018, it was Tensorflow , Keras, pytorch ( https://towardsdatascience.com/deep-learning-framework-power-scores-2018-23607ddf297a )
- but by 2023 this flipped, ( https://medium.com/@markurtz/2022-state-of-competitive-ml-the-downfall-of-tensorflow-e2577c499a4d )
how do Tensorflow / pytorch actually work on Databricks, or can they even?
I was wondering , do Horovod (from Uber), basically abstract away existance of the distributed environment ? Learned that mostly yes. But that TensorFlow , pytorch have some knowledge about the multiple clusters too.
Some libraries support multi-GPU
How much do you need to change your tensorflow, pytorch code?
According to https://horovod.readthedocs.io/en/stable/spark_include.html , your training code does need to rever to horovod like
from tensorflow import keras
import tensorflow as tf
import horovod.spark.keras as hvd
model = keras.models.Sequential()
.add(keras.layers.Dense(8, input_dim=2))
.add(keras.layers.Activation('tanh'))
.add(keras.layers.Dense(1))
.add(keras.layers.Activation('sigmoid'))
# NOTE: unscaled learning rate
optimizer = keras.optimizers.SGD(lr=0.1)
loss = 'binary_crossentropy'
store = HDFSStore('/user/username/experiments')
keras_estimator = hvd.KerasEstimator(
num_proc=4,
store=store,
model=model,
optimizer=optimizer,
loss=loss,
feature_cols=['features'],
label_cols=['y'],
batch_size=32,
epochs=10)
keras_model = keras_estimator.fit(train_df) \
.setOutputCols(['predict'])
predict_df = keras_model.transform(test_df)
and I get the impression that per the docs , MPI basically just uses spark workers as simple nodes, without rolling out the spark planning, say.
Horovod based on MPI.
Message Passing Interface (MPI)
So per https://mpitutorial.com/tutorials/mpi-introduction/ , MPI is a generic library for using a set of ip addressable hosts as nodes in a network.
Kubernetes too
Keras 3 approach
Similarly, Keras 3, has extended itself to make underlying JAX, tensorflow, pytorch libraries think they are talking to a single GPU device.
https://keras.io/guides/distribution/
different approaches, mapping to the partitioning strategies,
DataParallel, splitting up the data , mini-batches Each device has a local copy of model weights. https://keras.io/guides/distribution/#dataparallel
ModelParallel, cutting up the model weights when they are too large to fit on one device. https://keras.io/guides/distribution/#modelparallel-and-layoutmap
multi machine?
However digging into the docs, seeing DeviceMesh , etc but not how to scale to a cluster of nodes with many GPUS.
However, hmm tensorflow supports natively? tf.distribute.MirroredStrategy vs tf.distribute.MultiWorkerMirroredStrategy https://www.tensorflow.org/api_docs/python/tf/distribute/MultiWorkerMirroredStrategy
Multiple workers that are a "worker", but one of them is a "chief"
tf_config = {
'cluster': {
'worker': ['localhost:12345', 'localhost:23456']
},
'task': {'type': 'worker', 'index': 0}
}
What are the pyspark analogues for Kubernetes?
Dask, but reading perhaps not for >1TB size data.
example from the one billion row challenge
(from 2024-01-16 dask submission )
from dask.distributed import Client
import dask.dataframe as dd
client = Client()
df = dd.read_csv(
"measurements.txt",
sep=";",
header=None,
names=["station", "measure"],
engine='pyarrow',
dtype_backend='pyarrow'
)
df = df.groupby("station").agg(["min", "max", "mean"])
df.columns = df.columns.droplevel()
df = df.sort_values("station").compute()
their chart

however from polars’ website
Spark (specifically PySpark) represents a different approach to large-scale data processing. While Polars has an optimised performance for single-node environments, Spark is designed for distributed data processing across clusters, making it suitable for extremely large datasets.
However, Spark’s distributed nature can introduce complexity and overhead, especially for small datasets and tasks that can run on a single machine. Another consideration is collaboration between data scientists and engineers. As they typically work with different tools (Pandas and Pyspark), refactoring is often required by engineers to deploy data scientists’ data processing pipelines. Polars offers a single syntax that, due to vertical scaling, works in local environments and on a single machine in the cloud.
The choice between Polars and Spark often depends on the scale of data and the specific requirements of the processing task. If you need to process TBs of data, Spark is a better choice.
Seems like they make the same argument, w.r.t. the 1 TB figure.
Can you theoretically infinitely scale out , therefore , as wide as you wish?
parallelization strategies
data partitioning and allreduce .
TODO: go into
MPI
interestingly learned MPI , used by Horovod. More low level. From 1991.
MPI_RecvandMPI_Send. — AlsoMPI_Scatter, likemap. And aMPI_Bcast, send same message. — AndMPI_Gatheropposit of scatter.MPI_Reduce, appears to be also do the actual apply, instead of just retrieving.
Databricks , Kubernetes?
Learned the Kubernetes license is Apache, https://github.com/kubernetes/kubernetes/blob/master/LICENSE so private use is ok. Although couldn`t find disclosure on Databricks, and what is under the hood.
Also interesting comparison, distributed training and distributed inference
Thinking here since, was using hugging face spaces a bit and noticed ther is no cluster inference, but there is talk of model federation , in the agent space. Wondering abit the biggest of the biggest models.
some options:
pipeline parallelism: different layers across different GPUs.
compression: quantization of weights, down from high to lower precision floats, validating performance.
federation: use agent routing across to smaller more specialized models.
back prop distributed training approaches
Apparently there is a kind of distributed training where back prop gradient updates on minibatches are not synchronized. And can cause convergence to take longer or be harder (think lower learning rate suggested for those cases). So this is synchronous vs asynchronous. And yea
possible additional topics
- XGBoost built in parallelism
- Dask parallelization of scikit-learn via joblib.