Briefly describing this Streamlit fronted python app that queries against menus pulled from a kaggle uber eats dataset found here.
A Streamlit menu search
Mini screencast
First query something random

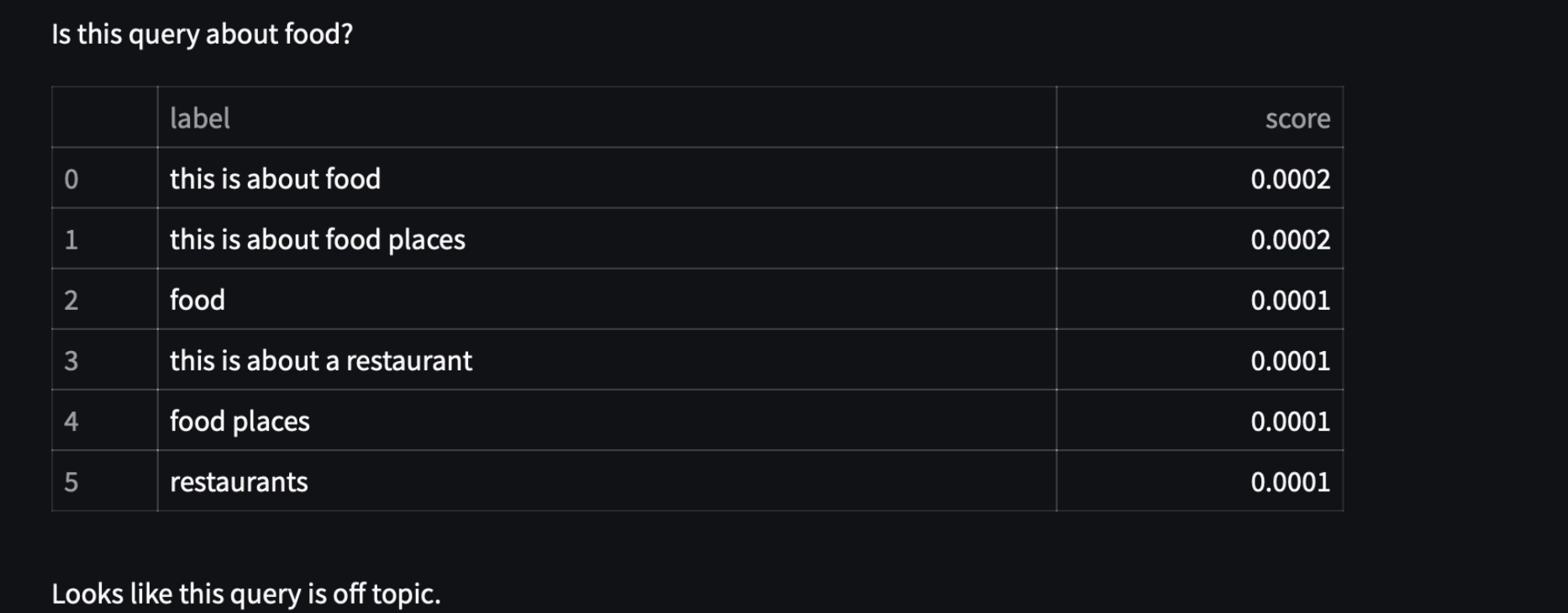
Continuing from an earlier post, this is taking advantage of Facebook’s BART model. A hugging face pipeline is used to hit against six food and restaurant related topics are averaged and compared against a threshold of 0.60 to determine if the query is food related. We see the topics are displayed with their level of entailment.
Now an on-topic query,
How about a query about chicken parmesan, which is a dish, so should be on topic.

And so the next part of the app is therefore run, which is to do a lookup against the local postgreql pgvector vector store, in this case using cohere embeddings.
We note at the bottom it says no location tokens found

"dbmdz/bert-large-cased-finetuned-conll03-english", which is a name entity recognition model.
If we try a query now that uses location information, that final result looks different.
And we split out the 'I-LOC' or location related information.
Source for this mini app
As a TODO, I should highlight some interesting snippets in this streamlit app, but for now, note, the source also lives here, https://github.com/namoopsoo/restaurant-menu-entities .
Under the hood
The streamlit app
There is a simple query box, tied to a function do_search,
with st.form(key='my_form'):
query = st.text_area("Input to search for.", key="my_query")
submit_button = st.form_submit_button(label='Search', on_click=do_search)
The first step in do_search is to check if the query is about food.
Topic check with BART
As described in more detail in an earlier post, bart-large-mnli is used as a hugging face pipeline, which means model blobs are cached ~/.cache/huggingface/hub/models--facebook--bart-large-mnli/ and loaded at inference time. This is a NLI (Natural Language Inference) model, meaning that given two sequences, logits for entailment, neutrality and contradiction are final outputs between those two sequences. And in particular, the entailment output is used as a so called zero-short sequence classifier, such that here, given six sequences related to food and dining, we can average these to get some idea about whether an input user query is about this topic, loosely.
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
def check_if_on_topic(query, topics):
classification = classifier(query, topics, multi_label=True)
return classification
def is_this_about_food(query):
topics = [
"this is about food",
"food",
"this is about a restaurant",
"restaurants",
"food places",
"this is about food places",
]
len_food_topics = len(topics)
classifications = check_if_on_topic(query, topics)
class_df = pl.from_records([classifications["labels"], classifications["scores"]], schema=["label", "score"])
food_pred = sum(classifications["scores"]) / len_food_topics
THRESHOLD = 0.65 # TODO can tune this.
on_topic = food_pred >= THRESHOLD
return class_df, on_topic, food_pred
If a query is on topic, next we do a vector search against postgresql pgvector
pg vector search
In this case, the initial kaggle dataset had been embedded with https://cohere.com embeddings, just since they were used in the langchain pgvector example, and they work out of the box with just an API key, but many other embedding models are available. It looks like this particular API, actually,
from langchain_cohere import CohereEmbeddings
, used under
from langchain_postgres.vectorstores import PGVector
, does not appear to cache the model locally as hugging face does. A good follow on step would be to look for a solution that caches the model locally, to reduce the inference latency.
Next, a BERT name entity recognition model is used to try to extract geolocation terms.
Use of NER
The https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english , pretrained to return, given a token sequence, a sequence of token entity labels, B-LOC/I-LOC, B-ORG/I-ORG, B-PER/I-PER when tokens are classified as entities and some non entity symbol like O when not. In this case, this is super useful in extracting tokens in the sequence correspondoing to locations, B-LOC/I-LOC because then this can potentially be used to filter against pgvector with more specific relational side of the input.
from transformers import pipeline
token_classifier = pipeline("ner")
print(token_classifier.model.name_or_path)
'dbmdz/bert-large-cased-finetuned-conll03-english'
We can take a peek at what the tokens are that this pipeline extracts,
query = (
"I'm on the corner of 14th stret and Broadway and I am trying to get to 59th street"
" and Central Park West ok how can I travel?"
)
tokens = token_classifier.tokenizer.tokenize(query, return_tensors="pt")
print(tokens)
['I', "'", 'm', 'on', 'the', 'corner', 'of', '14th', 's', '##tre', '##t', 'and', 'Broadway', 'and', 'I', 'am', 'trying', 'to', 'get', 'to', '59', '##th', 'street', 'and', 'Central', 'Park', 'West', 'ok', 'how', 'can', 'I', 'travel', '?']
And here is the classification part, only for the entity tokens,
preds = token_classifier(query)
preds = [
{
"entity": pred["entity"],
"score": round(pred["score"], 4),
"index": pred["index"],
"word": pred["word"],
"start": pred["start"],
"end": pred["end"],
}
for pred in preds
]
print("DEBUG ner extract.")
print(*preds, sep="\n")
DEBUG ner extract.
{'entity': 'I-LOC', 'score': 0.8308, 'index': 8, 'word': '14th', 'start': 21, 'end': 25}
{'entity': 'I-LOC', 'score': 0.9737, 'index': 13, 'word': 'Broadway', 'start': 36, 'end': 44}
{'entity': 'I-LOC', 'score': 0.7358, 'index': 21, 'word': '59', 'start': 71, 'end': 73}
{'entity': 'I-LOC', 'score': 0.749, 'index': 22, 'word': '##th', 'start': 73, 'end': 75}
{'entity': 'I-LOC', 'score': 0.9923, 'index': 25, 'word': 'Central', 'start': 87, 'end': 94}
{'entity': 'I-LOC', 'score': 0.9966, 'index': 26, 'word': 'Park', 'start': 95, 'end': 99}
{'entity': 'I-LOC', 'score': 0.9964, 'index': 27, 'word': 'West', 'start': 100, 'end': 104}
So now we know how to split out location tokens from a query.